k-Nearest Neighbour (kNN)
The kNN algorithm is a simple but extremely powerful classification algorithm. Tie name of the algorithm originates from the underlying philosophy of kNN —i.e. people having similar background or mindset tend to stay close to each other. In other words, neighbours in a locality have a similar background. In the same way, as a part of the kNN algorithm, the unknown and unlabelled data which comes for a prediction problem is judged on the basis of the training data set elements which are similar to the unknown element. So, the class label of the unknown element is assigned on the basis of the class labels of the similar training data set elements (metaphorically can be considered as neighbours of the unknown element). Let us try to understand the algorithm with a simple data set.
How kNN works
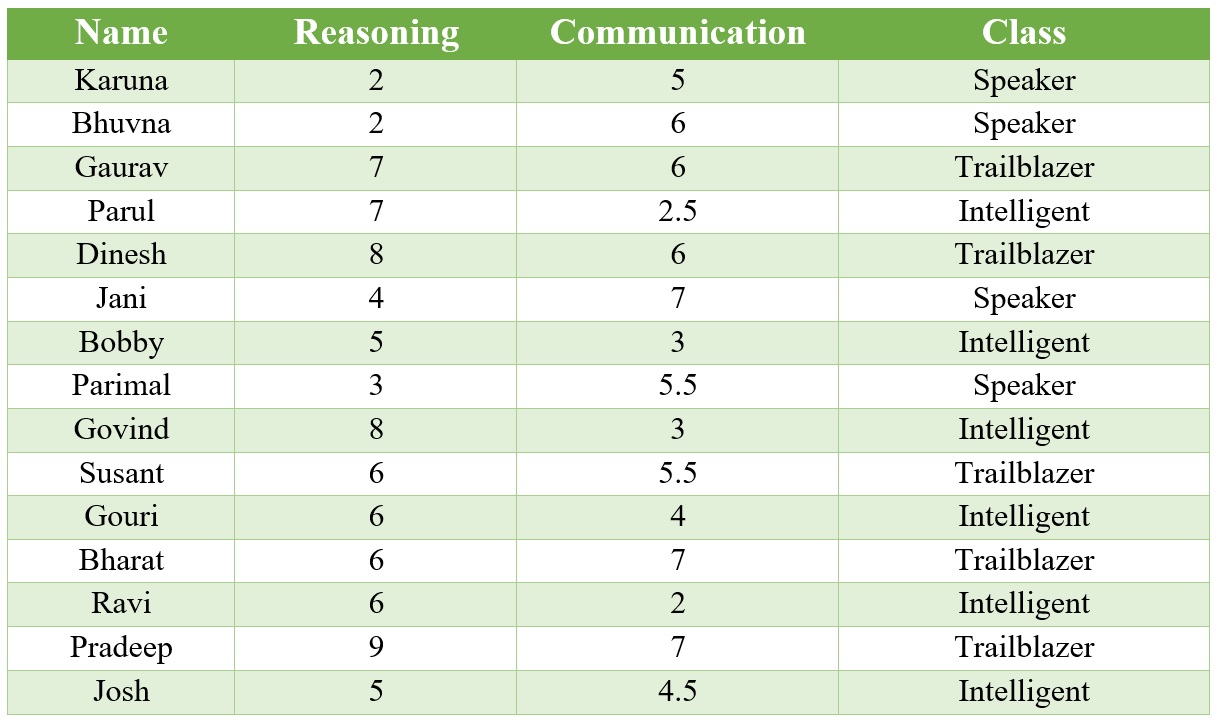
Let us consider a very simple Student data. It consists of 15 students studying in a class. Each of the students has been assigned a score on a scale of 10 on two performance parameters — Reasoning and 'Communication'. Also, a class value is assigned to each student based on the following criteria:
1: Students having good communication skills as well as a good level of Reasoning have been classified as 'Leader'
2: Students having good communication skills but not so good level of Reasoning has been classified as 'Speaker'
3: Students having not so good communication skill but a good level of aptitude has been classified as ‘Intelligent’
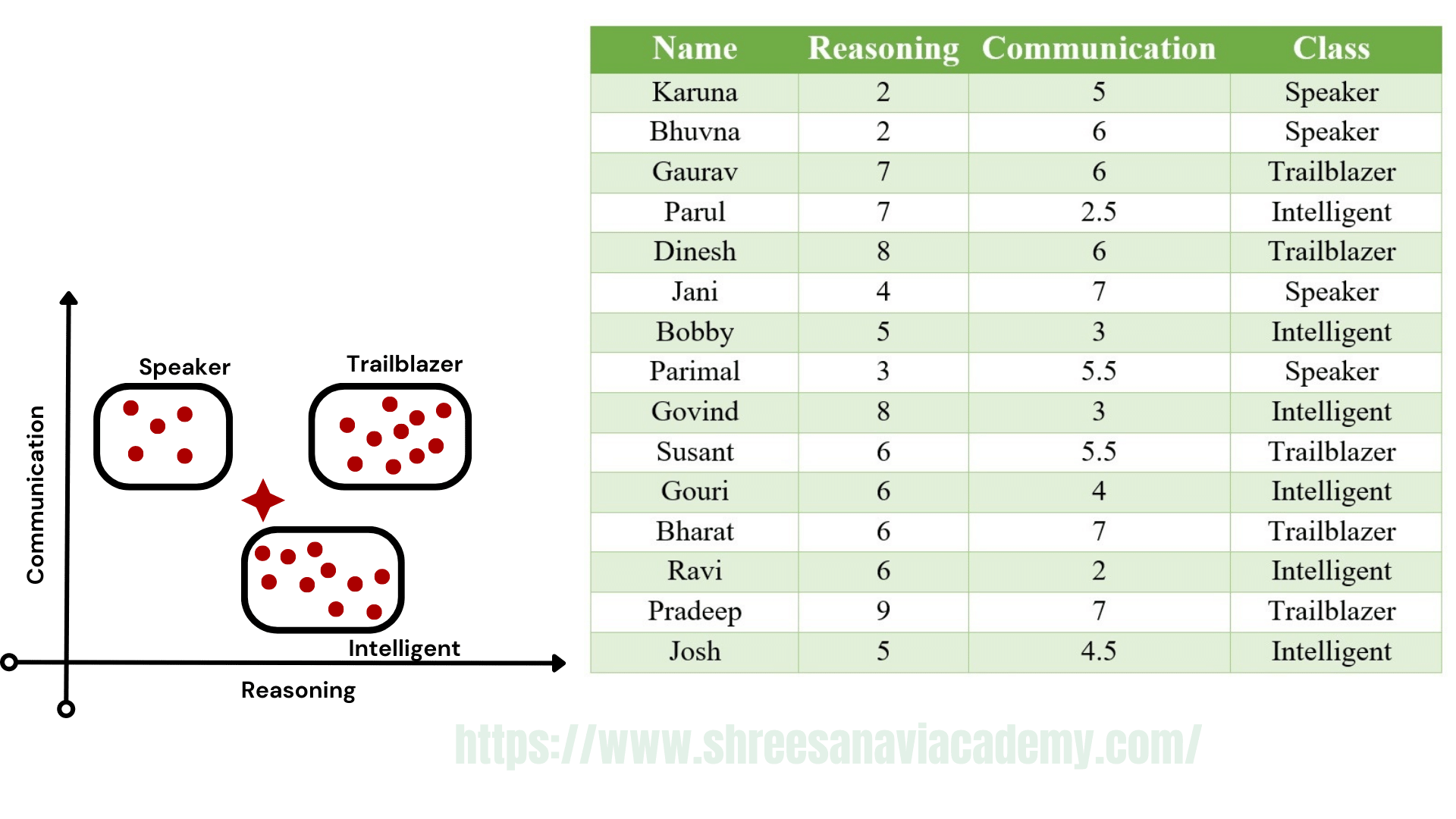
In the kNN algorithm, the class label of the test data elements is decided by the class label of the training data elements which are neighbouring, i.e. similar in nature. But there are two challenges:
1: What is the basis of this similarity or when can we say that two data elements are similar?
2: How many similar elements should be considered for deciding the class label of each test data element?
To answer the first question, though there are many measures of similarity, the most common approach adopted by kNN to measure similarity between two data elements is Euclidean distance. Considering a very simple data set having two features (say f1 and f2), Euclidean distance between two data elements d1 and d2 can be measured by
![]()
where
f11 = value of feature f1 for data element d1
f12 = value of feature f1 for data element d2
f21 = value of feature f2 for data element d1
f22 = value of feature f2 for data element d2
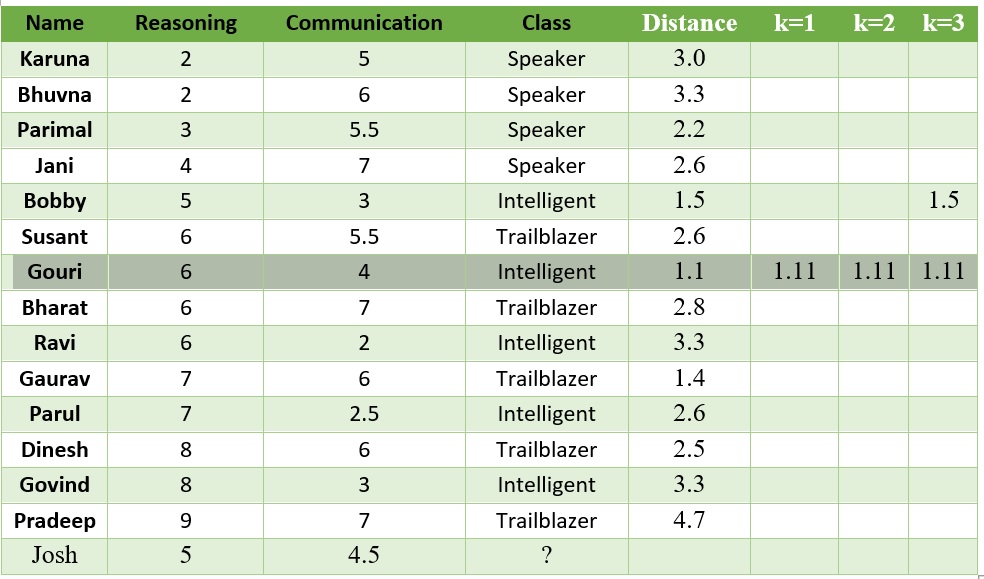
Let us now try to find out the outcome of the algorithm for the student data set we have. In other words, we want to see what class value kNN will assign for the test data for student Josh. When the value of k is taken as 1, only one training data point needs to be considered. The training record for student Gouri comes as the closest one to test record of Josh, with a distance value of 1.11. Gouri has class value Intelligent. So, the test data point is also assigned a class label value ' Intelligent '. When the value of k is assumed as 3, the closest neighbours of Josh in the training data set are Gouri, Susant, and Bobby with distances being 1.11, 1.4, and 1.5, respectively. Gouri and Bobby have class value
' Intelligent', while Susant has class value Trailblazer. In this case, the class value of Josh is decided by majority voting. Because the class value of Intelligent is formed by the majority of the neighbours, the class value of Josh is assigned as Intelligent. This same process can be extended for any value of k.
kNN Algorithm
Input: Training data set, test data set (or data points), value of 'k' (i.e. number of nearest neighbours to be considered)
Steps:
Do for all test data points
Calculate the distance (usually Euclidean distance) of the test data point from the different training data points.
Find the closest 'k' training data points, i.e. training data points whose distances are least from the test data point.
if k=l
Then assign class label of the training data point to the test data point
else
Whichever class label is predominantly present in the training data points, assign that class label to the test data point
end do
Advantages of the kNN algorithm
-
Extremely simple algorithm
-
easy to understand
-
Very effective in certain situations, e.g. for recommender system design
-
Very fast or almost no time required for the training phase
Drawback of the kNN algorithm
-
In a real sense, he does not learn anything. The classification is entirely based on the training data. As a result, it is heavily reliant on training data. If the training data does not adequately represent the problem domain, the algorithm will fail to make an accurate classification.
-
Because there is no model trained in real sense and the classification is done completely on the basis of the training data, the classification process is very slow.
-
Also, a large amount of computational space is required to load the training data for classification.
machine learning, machine learning algorithms, machine learning algorithms meaning, machine learning algorithms definition, machine learning algorithms tutorial, machine learning supervised unsupervised reinforcement, machine learning supervised learning, supervised learning algorithms, unsupervised learning, unsupervised learning vs supervised learning, machine learning tutorial, machine learning tutorial pdf, shreesanavi Academy Tutorial