Unsupervised Learning
Unsupervised learning does not use labelled training data like supervised learning does, so no predictions can be made. Unsupervised learning aims to discover clusters or patterns within the data elements or records of a dataset as input. 'Therefore, unsupervised learning is often termed as descriptive model and the process of unsupervised learning is referred as pattern discovery or knowledge discovery. One critical application of unsupervised learning is customer segmentation.
The most common form of unsupervised learning is clustering. It aims to organise or group together things that are similar. Because of this, objects that belong to the same cluster are very similar to one another, whereas objects that belong to different clusters are very different. As a result, the goal of clustering is to identify the natural grouping of unlabeled data and create clusters. As shown in the following figure, various measures of similarity can be used for clustering. Distance is one of the most widely used similarity measures.
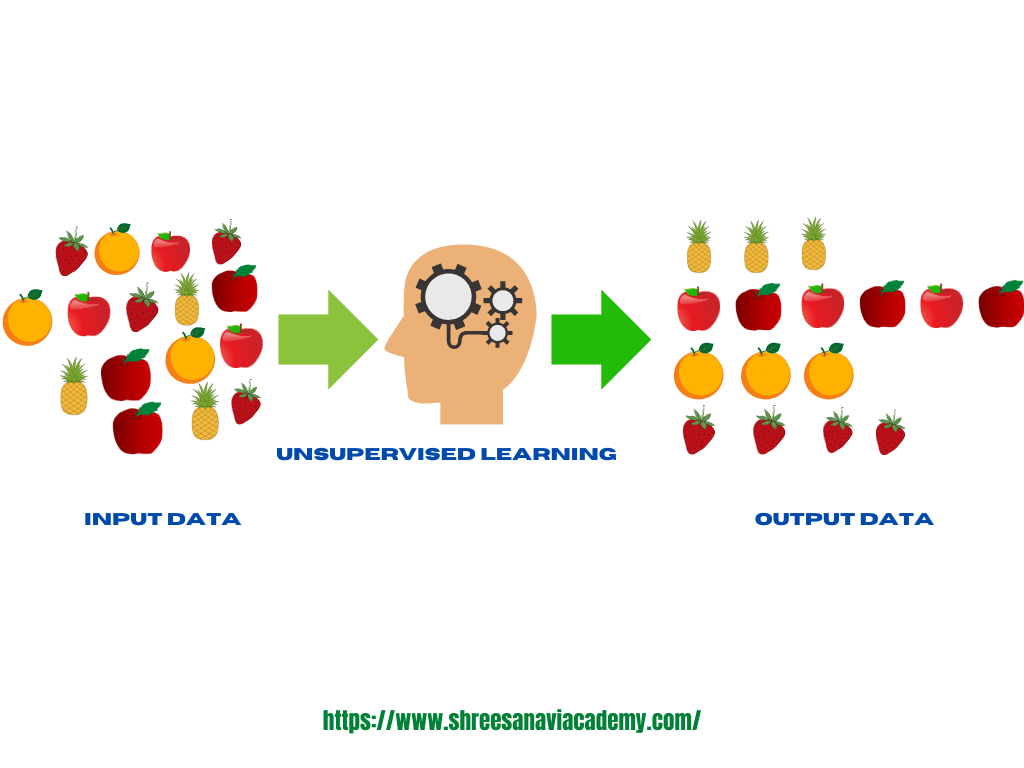
If there is less distance between two pieces of data, they are regarded as belonging to the same cluster. In the same way, items generally do not belong to the same cluster if there is a large distance between them. Another name for this is distance-based clustering. High-level clustering is illustrated in follwoing figure. Association analysis is another form of unsupervised learning in addition to data clustering and obtaining a consolidated view from it.