Classification
The labelled training data serve as the foundation for learning in supervised learning. This tagged training data is the experience, previous knowledge, or belief, according to the definition of machine learning. It is named supervised learning because the process of a machine learning from training data may be compared to a teacher monitoring the learning process of a new pupil. The instructor serves as the training data in this case.
Supervised machine learning is as good as the data used to train it. If the training data is poor in quality, the prediction will also be far from being precise.
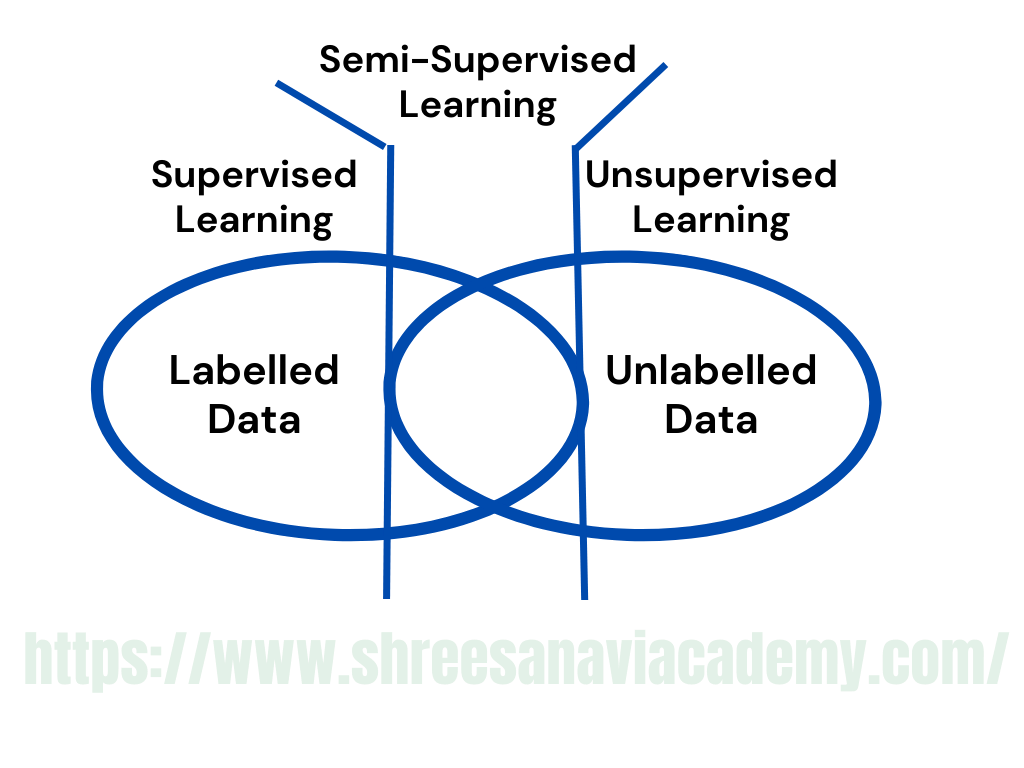
Training data is the past information with known value of class field or 'label'. Hence, we say that the 'training data is labelled' in the case of supervised learning. Contrary to this, there is no labelled training data for unsupervised learning. Semi-supervised learning, as depicted in in following figure, uses a small amount of unlabelled data along with labelled data for training.
Examples of supervised learning are as follows.
- Prediction of results of a game based on the past analysis of results
- Predicting whether a tumour is malignant or benign on the basis of the analysis of data
- Price prediction in domains such as real estate, stocks, etc,