Machine Learning Activities
Data is the first step in any machine learning activity. In supervised learning, the labelled training data set is followed by the unlabeled test data. In the case of unsupervised learning, the task is to identify patterns in the input data since there is no need for labelled data. To comprehend the type of data, the quality of the data, and the relationships between the various data elements, a thorough review and exploration of the data are required. Accordingly, before we can move forward with the main machine learning operations, the input data may need to undergo a number of pre-processing operations.
Following are the typical preparation activities done once the input data comes into the machine learning system:
-
Understand the type of data in the given input data set.
-
Explore the data to understand the nature and quality.
-
Explore the relationships amongst the data elements, e.g. inter-feature relationship.
-
Find potential issues in data.
-
Do the necessary remediation, e.g. impute missing data values, etc., if needed.
-
Apply pre-processing steps, as necessary.
-
Once the data is prepared for modelling, then the learning tasks start off. As a part of it, do the following activities:
-
-
The input data is first divided into parts — the training data and the test data , and this step is applicable only for supervised learning.
-
Consider different models or learning algorithms for selection.
-
For supervised learning problems, build a model based on training data and apply it to unknowable data. Use the selected unsupervised model to solve the unsupervised learning problem directly on the input data.
-
-
The performance of the model is assessed after it has been chosen, trained (for supervised learning), and used on input data. If possible, specific actions can be taken to enhance the model's performance based on the options available.
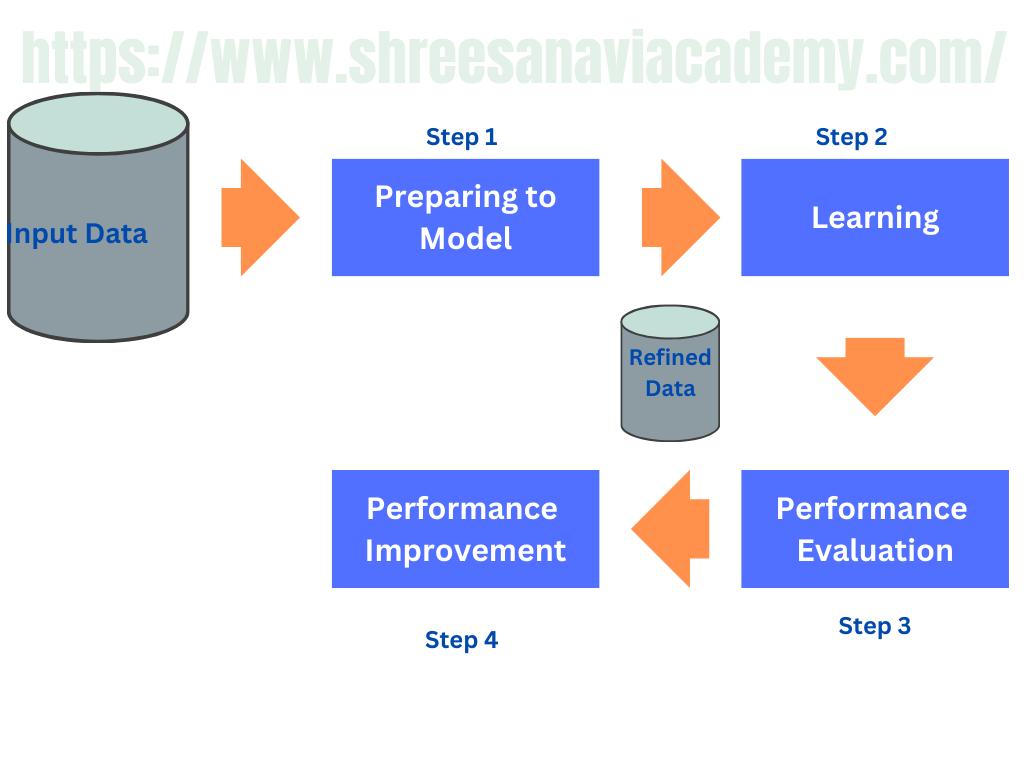
Figure: Detailed Process of Machine Learing
Activities in Machine Learning:
Step1: Preparing to Model
-
Understand the type of data in the given input data set
-
Explore the data to understand data quality
-
Explore the relationships amongst the data elements, e.g. interfeature relationship
-
Find potential issues in data
-
Remediate data, if needed
-
Apply following pre-processing steps, as necessary:
-
Dimensionality reduction
-
Feature subset selection
Step 2: Learning
-
Data partitioning/holdout
-
Model selection
-
Cross-validation
Step 3: Performance Evaluation
-
Examine the model performance, e.g. confusion matrix in case of classification
-
Visualize performance trade-offs using ROC curves
Step 4: Performance improvement
-
Tuning the model
-
Ensembling (Improving the Accuracy of Results)
-
Bagging
-
Boosting