Supervised Learning
The primary motivation for supervised learning is to learn from previous information. So, what type of prior knowledge does the machine require for supervised learning? It contains information about the task that the machine must complete. This previous information is referred to as experience in the context of the notion of machine learning. Let us try to explain it with an example. Assume a machine receives images of various items as input and the job is to separate the images based on the shape or colour of the object. If it is by shape, photographs of round-shaped objects must be segregated from images of triangular-shaped objects, and so on. If colour segregation is required, photos of blue things must be segregated from images of green objects. But how does the machine recognise whether a shape is round or triangular? In the same way, how can a machine tell whether an image of an object is blue or green? A machine is similar to a small child who needs to be guided by his parents or adults with basic information about shape and colour before he can begin performing the activity. A machine requires basic information to function. This basic input, or experience in the machine learning paradigm, is provided in the form of training data. Past information on a specific task is referred to as liaining data. In the context of the image segregation problem, training data will include previous data on various elements or properties of a number of photos, as well as a tag indicating whether the image is round, triangular, blue, or green in colour. In the case of supervised learning, the tag is called a 'label,' and the training data is labelled.
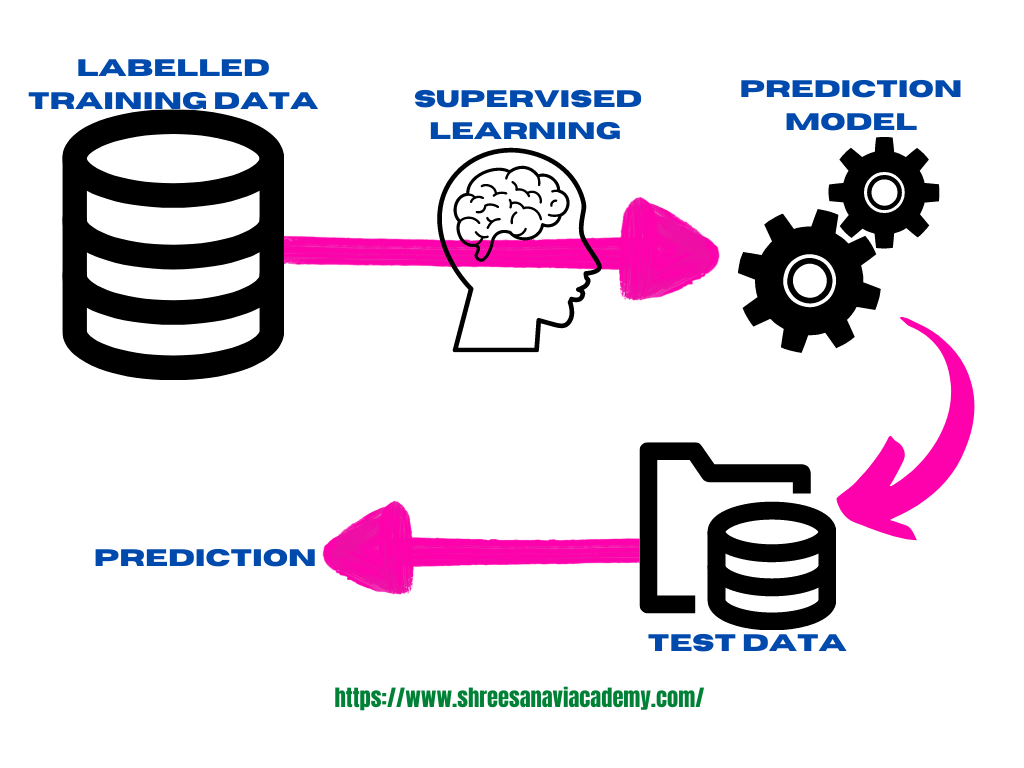
The image below depicts a simplified representation of the supervised learning process. As an input, labelled training data including past information is provided. The machine creates a predictive model based on the training data that can be used on test data to assign a label to each record in the test data.
Some examples of supervised learning are
-
Predicting the results of a game
-
Predicting whether a tumour is malignant or benign
-
Predicting the price of domains like real estate, stocks, etc.
-
Classifying texts such as classifying a set of emails as spam or non-spam
Consider two of the above examples: forecasting whether a tumour is malignant or benign and predicting the price of areas such as real estate. Are these two issues similar in nature? No, it does not. Though both are prediction problems, in one we are attempting to forecast which category or class given unknown data belongs to, and in the other we are attempting to predict an absolute value rather than a category. A classification challenge occurs when we attempt to predict a category or nominal variable. When attempting to forecast a real-valued variable, the problem is classified as regression.