Classification Model
Training data is the past information with known value of class field or 'label'. Hence, we say that the 'training data is labelled' in the case of supervised learning. Contrary to this, there is no labelled training data for unsupervised learning. Semi-supervised learning, as depicted in in following figure, uses a small amount of unlabelled data along with labelled data for training.
Consider two examples: 'predicting whether a tumour is malignant or benign' and 'price prediction in the real estate industry'. Are these two issues similar in nature? No, it does not. It is true that both of these are prediction issues. In the case of tumour prediction, however, we are attempting to forecast whether category or class, i.e.'malignant' or 'benign,' given unknown input data connected to tumour belongs to. In the opposite example, when predicting prices, we are attempting to anticipate an absolute value rather than a class. A classification challenge occurs when we attempt to predict a category or nominal variable. A classification issue is one in which the output variable is a category such as "red," "blue," "malignant tumour," "benign tumour," and so on. When we attempt to forecast a numerical variable such as 'price,' 'weight,' etc., the issue is classified as regression.
We can observe that in classification, the whole problem centres around assigning a label or category or class to a test data on the basis of the label or category or class information that is imparted by the training data. Because the target objective is to assign a class label, we call this type of problem as a classification problem. Following figure depicts the typical process of classification where a classification model is obtained from the labelled training data by a classifier algorithm. A critical classification problem in the context of the banking domain is identifying potentially fraudulent transactions. Because there are millions pf transactions which have to be scrutinized to identify whether a particular transaction might be a fraud transaction, it is not possible for any human being to carry out this task. Machine learning is leveraged efficiently to do this task, and this is a classic case of classification. On the basis of the past transaction data, especially the ones labelled as fraudulent, all new incoming transactions are marked or labelled as usual or suspicious. The suspicious transactions are subsequently segregated for a closer review.
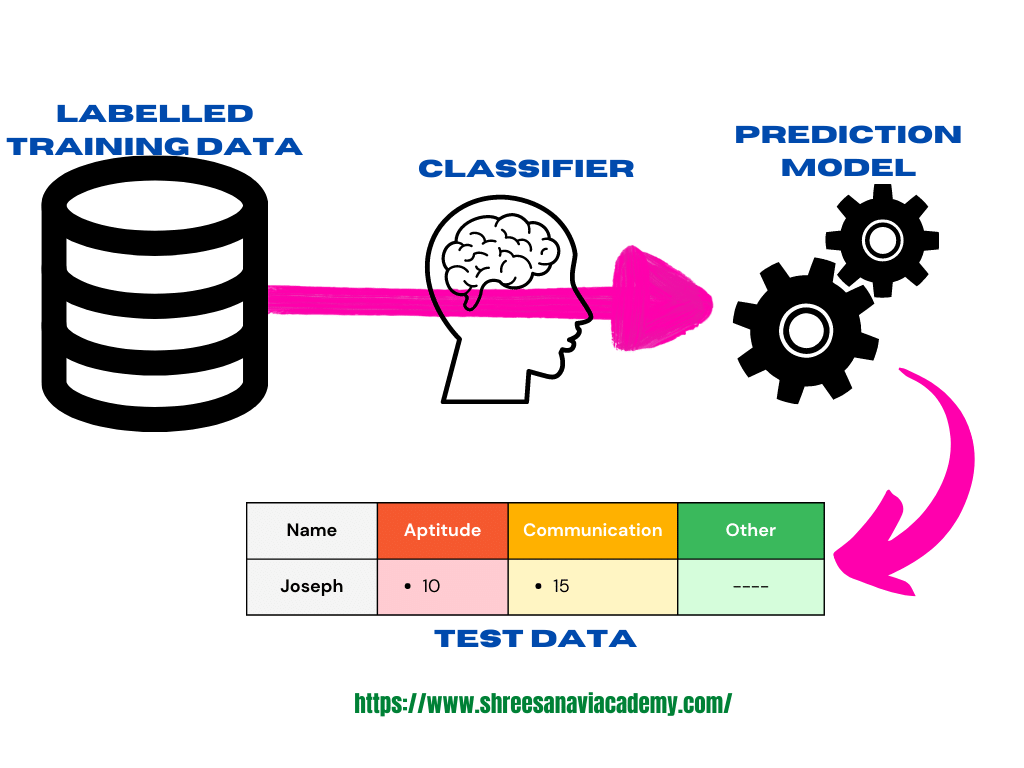
In summary, Classification is a kind of supervised learning in which a categorical target feature is predicted for test data based on the knowledge given by the training data. Class is the desired category characteristic.
Some typical classification problems include the following:
- Image classification
- Disease prediction
- Win—loss prediction in games
- Prediction of natural disaster like earthquake, flood, etc.
- Handwriting recognition