Classification Learning Steps
First, there is a problem which is to be solved, and then, the required data (related to the problem, which is already stored in the system) is evaluated and pre-processed based on the algorithm. Algorithm selection is a critical point in supervised learning. "The result after iterative training rounds is a classifier for the problem in hand.
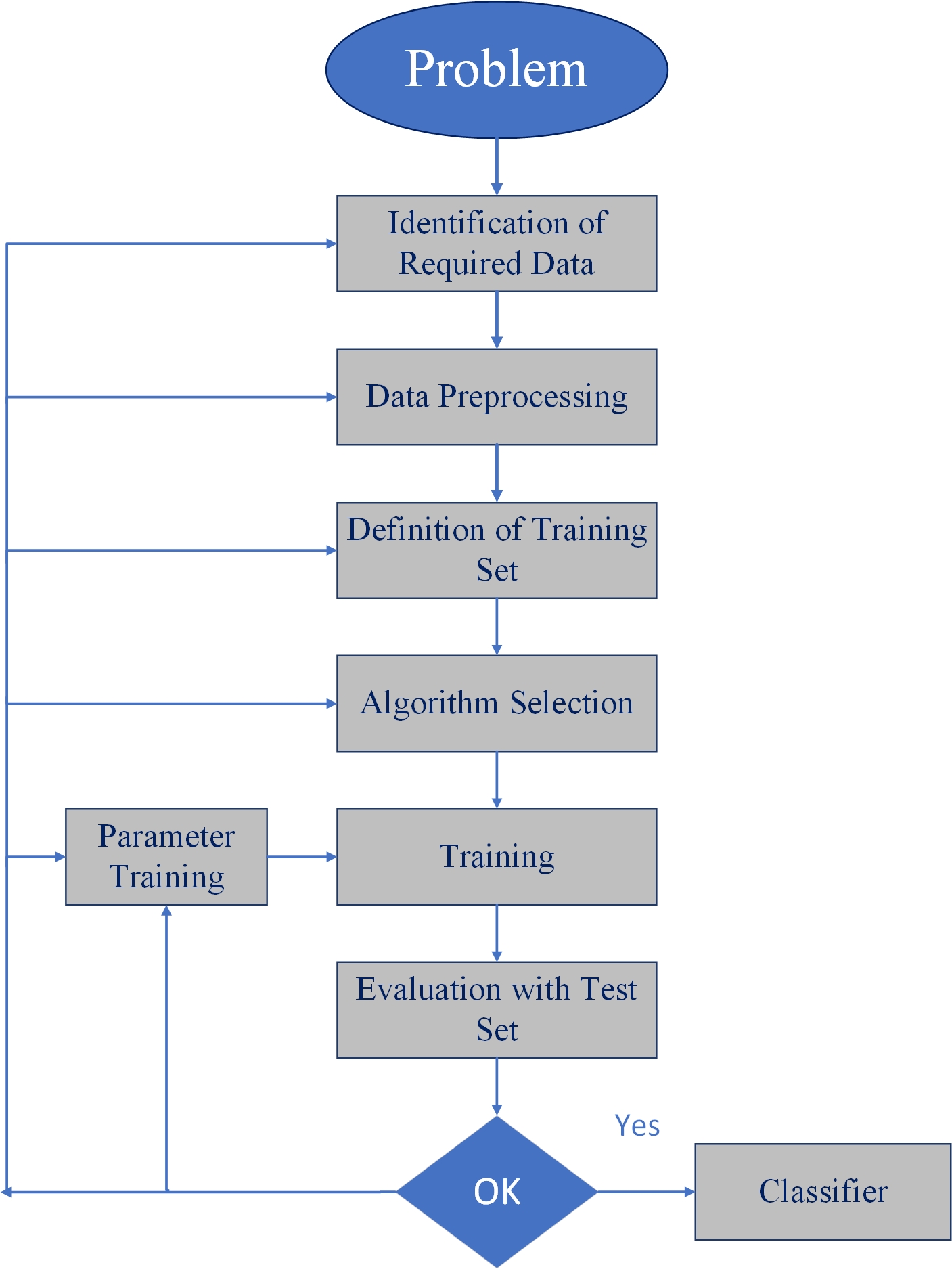
Problem Identification: The first step in the supervised learning model is to identify the problem. The problem needs to be a well-formed problem, i.e. a problem with well-defined goals and benefit, which has a long-term impact.
Identification of Required Data: The required data set that precisely represents the identified problem must be identified/evaluated based on the problem identified above. For example: If the problem is to predict whether a tumour is malignant or benign, then the corresponding patient data sets related to malignant tumour and benign tumours are to be identified.
Data Pre-processing: This is related to the data set cleaning/transformation. This step ensures that all irrelevant/unnecessary data elements are removed. Data pre-processing refers to the transformations performed on identified data prior to feeding it into the algorithm. Because the data is gathered from various sources, it is usually collected in raw format and is not immediately ready for analysis. This step ensures that the data is ready to be fed into the machine learning algorithm.
Definition of Training Data Set: Before starting the analysis, the user should decide what kind of data set is to be used as a training set. In the case of signature analysis, for example, the training data set might be a single handwritten alphabet, an entire handwritten word (i.e. a group of the alphabets) or an entire line of handwriting (i.e. sentences or a group of words). Thus, a set of 'input meta-objects' and corresponding 'output meta-objects' are also gathered. The training set needs to be actively representative of the real-world use of the given scenario. Thus, a set of data input (X) and corresponding outputs (Y) is gathered either from human experts or experiments.
Algorithm Selection: The structure of the learning function and the corresponding learning algorithm must be determined. This is the most important step in the supervised learning model. The best algorithm for a given problem is chosen based on a variety of parameters.
Training: The learning algorithm identified in the previous step is run on the gathered training set for further fine tuning. Some supervised learning algorithms require the user to determine specific control parameters (which are given as inputs to the algorithm). These parameters may also be adjusted by optimizing performance on a subset of the training set.
Evaluation with the Test Data Set: Training data is run on the algorithm, and its performance is measured here. If a suitable result is not obtained, further training of parameters may be required.
Common Classification Algorithms
Following are the most common classification algorithms.
- k-Nearest Neighbour (kNN)
- Decision tree
- Random Forest
- Support Vector Machine (SVM)
- Naive Bayes classifier