Basics of Feature Engineering
Feature engineering is an important pre-processing step in machine learning. It is in charge of converting raw input data into well-aligned features that are ready to be used by machine learning models.
A feature is a data set attribute that is used in a machine learning process. Certain machine learning practitioners believe that only attributes that are meaningful to a machine learning problem should be called features, but this viewpoint should be taken with a grain of salt. In fact, selecting the subset of features that are meaningful for machine learning is a sub-area of feature engineering that has received a lot of attention from researchers. A data set's features are also referred to as its dimensions. As a result, a data set with 'n' features is referred to as an n-dimensional data set.
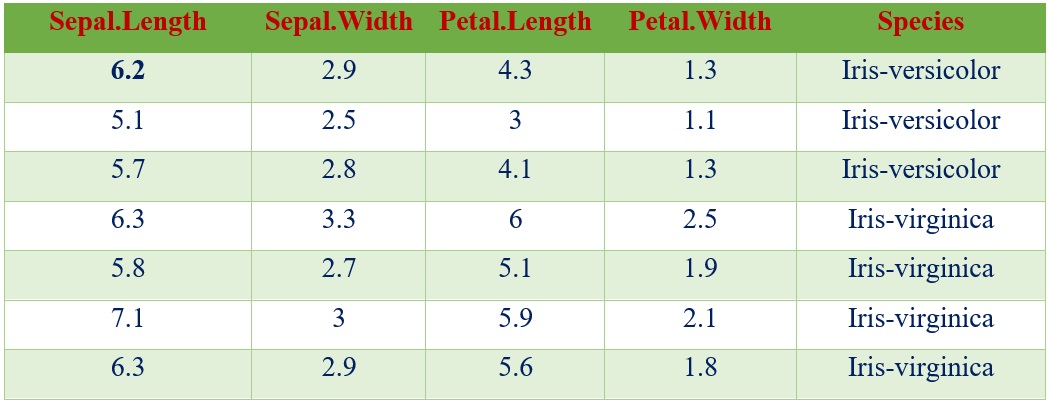
Let's take the example of a famous machine learning data set, Iris, introduced by the British statistician and biologist Ronald Fisher, partly shown in following table. It has five characteristics or attributes, which are Sepal.Length, Sepal.Width, Petal.Length, Petal. Width, and Species. The feature 'Species' represents the class variable, while the remaining features are predictor variables. It is a data set with five dimensions.
What is feature engineering?
The process of translating a data set into features so that these features can more effectively represent the data set and result in better learning performance is referred to as feature engineering.
The Feature engineering is an important pre-processing step for machine learning. It has two major elements:
- Feature Transformation
- Feature Subset Selection
Feature Transformation: Transforms structured or unstructured data into a new set of features that can represent the problem that machine learning is attempting to solve. Two variants of feature transformation exist:
- Feature Construction
- Feature Extraction
Both are sometimes known as feature discovery
Feature construction process discovers missing information about the relationships between features and augments the feature space by creating additional features. Hence, if there are 'n' features or dimensions in a data set, after feature construction 'm' more features or dimensions may get added. So at the end, the data set will become 'n + m' dimensional.
Feature extraction refers to the process of extracting or generating a new set of features from the original set of features using functional mapping.
Feature Subset Selection: Unlike feature transformation, in case of feature subset selection (or simply feature selection) no new feature is generated. The objective of feature selection is to derive a subset of features from the full feature set which is most meaningful in the context of a specific machine learning problem. So, essentially the job of feature selection is to derive a subset Fj (Fl, F2, ..., Fm) of Fi (Fl, F2, ..., Fn), where m < n, such that Fj is most meaningful and gets the best result for a machine learning problem.